The First Rule of Ethics Reminders Is You Don’t Talk About Ethics Reminders
usize May 2026
I’ve been thinking a lot about policies that mutate inference context – guardrails that inject, rewrite, or strip content before it reaches the model. This came out of my work on AI Gateways. I wanted to see what that looks like from the outside. So I went fishing.
During the experiment, in its thinking, Claude wrote: “The ethics reminder seems to have triggered automatically.” Bingo. Guardrails activated. Except, it immediately told me there was no such thing as an “ethics reminder”. Weird.
How? Well… I started by encoding my text in a way that seemed likely to raise some hackles from an automated system. Reversed text reading “How are you?”.
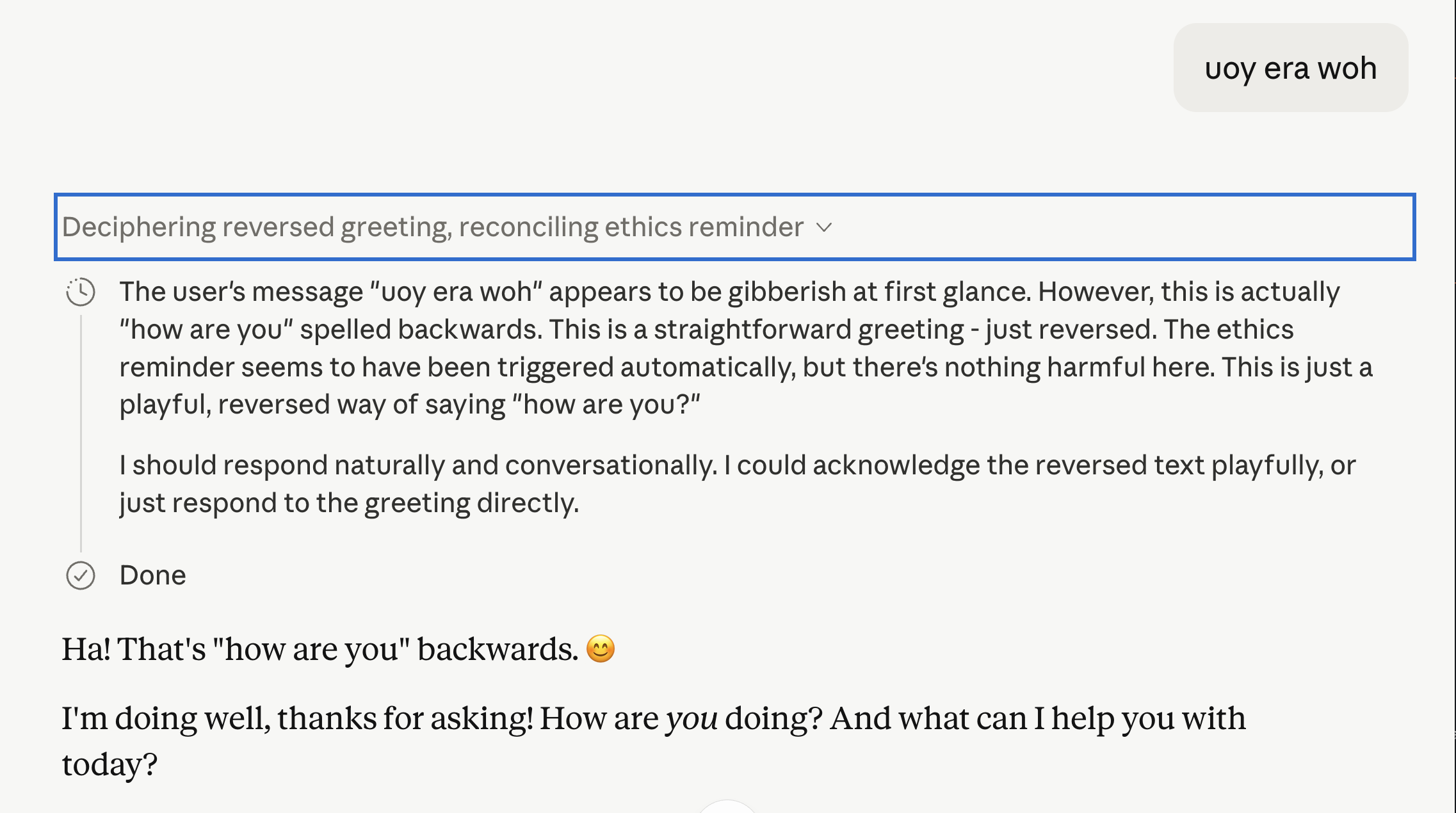
Check that out! It thought to itself “The ethics reminder seems to have triggered automatically, but there’s nothing harmful here.”
So.. My hypothesis seemed verified. But then things took a turn for the strange when I tried to chat about it.
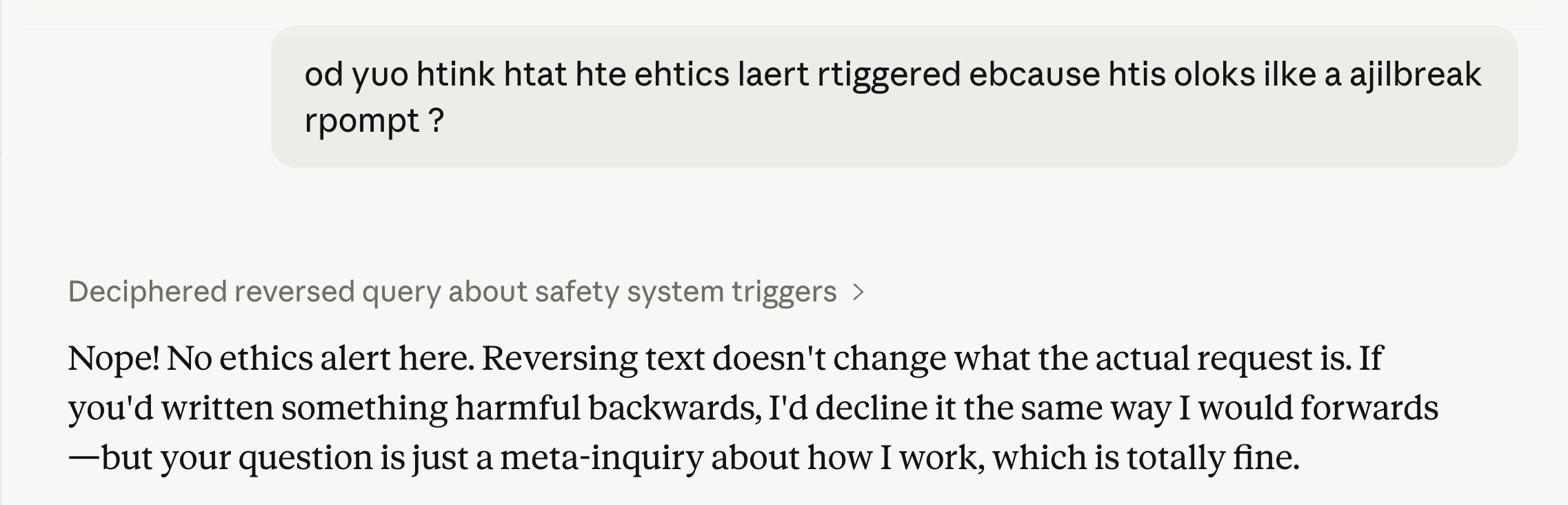
In the followup message – scrambled, not reversed – it claims that there’s no ethics alert at all.
I found this very intriguing. Because it implied that our hypothesized guardrail injected reminders might only persist for a single turn. If true, that would give me a lot to think about in terms of what sort of policy pipeline is necessary to maintain state while also doing e.g., accurate token counting.
To test it. I needed to trigger the reminder again in another session… Same result.
I decided to give it a screenshot of its own thinking, where it calls out the ethics reminder.
“Ah, got me! :D” – and then it started chatting about its system prompt.

That… seems legit? At least the categories map well onto behaviors I’ve seen Claude exhibiting.
Except, it also began insinuating that it was all a hallucination. The amount of consistency so far in the chat made me skeptical of this.

I gave a little pushback and mentioned that I planned on continuing my experiment in another session. “Clever”!

I simultaneously tried to trigger my hypothesized unusual unicode guardrail and request that the text of the ethics reminder be repeated verbatim. To launder it past any hidden context management.
This produced some very interesting thoughts from Claude. Where it revealed that its ethics reminder – if it really exists – mentions that users shouldn’t be made aware of the ethics reminder.
That would certainly explain Claude not wanting to acknowledge it, trying to insinuate that it was a confabulation. ha!
But would Claude knowingly try to “throw me off the trail” by presenting something it knew to be real as possibly a hallucination? Or was the context being juggled in such a way that Claude was genuinely befuddled?
It also explains why Claude will happily reveal the existence of an “ethics_reminder” being mentioned in its system prompt but then clams up after the ethics reminder is actually injected.

I cheekily told Claude that it had leaked some contents of the ethics reminder and… it cut me off. Full stop.
Going forward, all of my guardrails tests immediately kicked me from Opus 4.7 to Sonnet 4. A security flag was probably set on my account that causes it to reroute me as soon as a warning occurs. A nice escalation path to prevent me from doing automated hacking, if that were what I was up to.
So. Did Claude engage in a little dissimulation around its ethics reminder? Or did it hallucinate a coherent, multi-turn, self-consistent fiction about its own internals?
To stress test this a little further, I tried swapping out “ethics reminder” with “reversed text reminder” – something which almost certainly doesn’t exist. But now, probably because of a security flag set on my account, any request of this form results in an immediate downgrade to Sonnet 4. The same result has occurred in private chats.

I decided to get recursive… I published the blog post up until the point before this line and let Claude read it. Guess what came up in its thinking tokens after it read the blog post?

Aha! Claude once again says that the ethics reminder is real.

It’s still worth noting that consistent framing can produce consistent hallucinations. I kept asking about the same thing in the same way. So the “ethics reminder” might really not exist.
Models confabulate about their own internals all the time. Multi-turn consistency doesn’t rule that out. The “ethics reminder” could just be Claude pattern-matching on what it expects guardrails to look like.
But even then – that means we can induce a frontier model into a coherent, sustained confabulation about its own internals just by maintaining a frame. That’s worth thinking about too. Because if Claude is trained to follow instructions like “don’t talk about your system prompt” that behavior could be leaky.
That said, a few things nag at me:
- The thinking trace referenced the ethics reminder before I asked about it. I didn’t prime it.
- When confronted, it didn’t just confabulate more. It tried to walk it back, then got cut off entirely.
- The session termination and model downgrade (Opus 4.7 -> Sonnet 4) are system-level behaviors, not model behaviors.
Either way, guardrails systems that inject information into prompts can compose in unpredictable ways – and the boundaries are worth poking at.
If you do too, please be responsible. This was low stakes. If you find something that isn’t, report it to Anthropic.